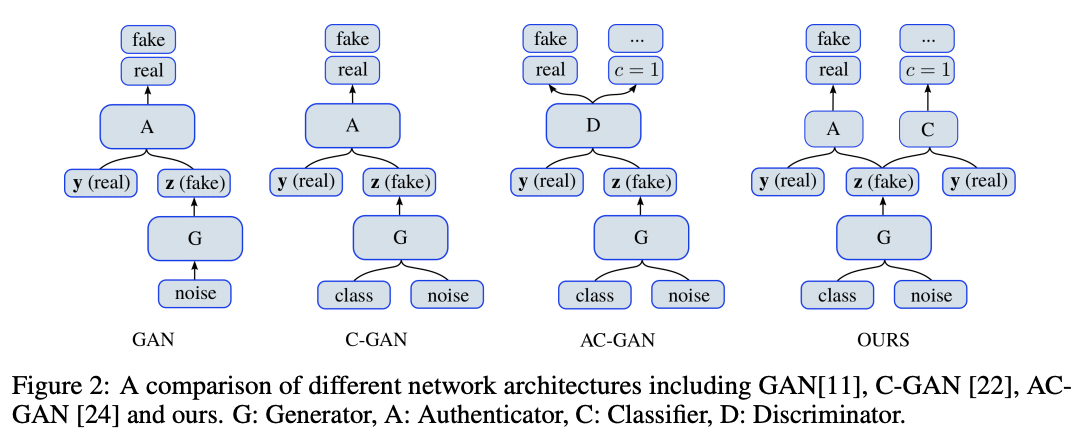
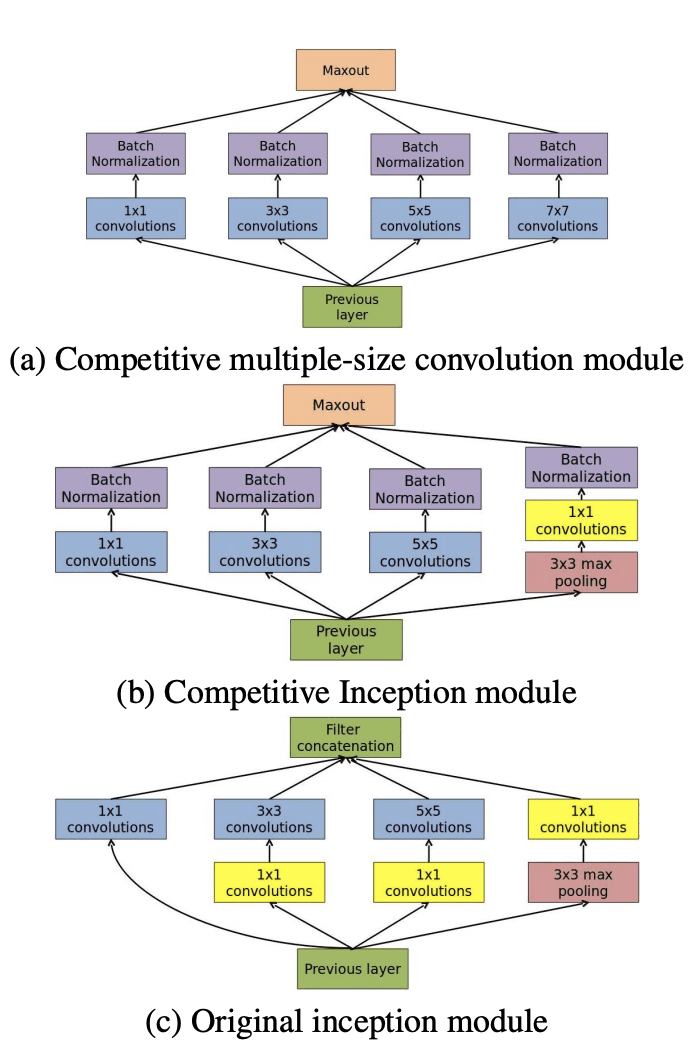
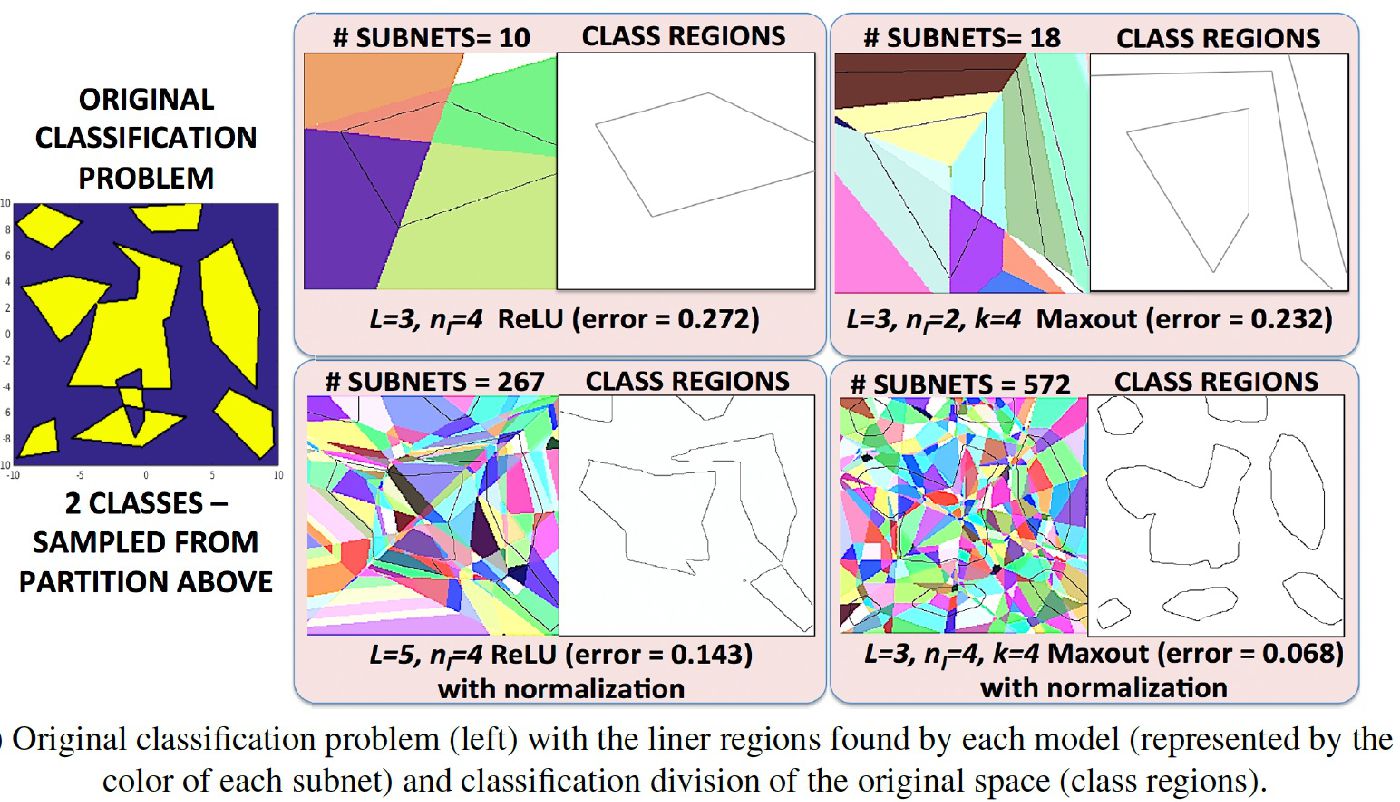
Self-supervised Monocular Trained Depth Estimation using Self-attention and Discrete Disparity Volume
In this paper, we propose two new ideas to improve self-supervised monocular trained depth estimation: 1) self-attention, and 2) discrete disparity prediction.